
写在最前
目前不论是 LoongArch 还有 RISCV 能兼容的 Phoronix 性能测试模块并不多,我利用目前能够使用的做了一些跑分,其实这些跑分在官方提供的幻灯片都已经提到,并且在油管和B站都有很多自媒体做了测试。比方说:
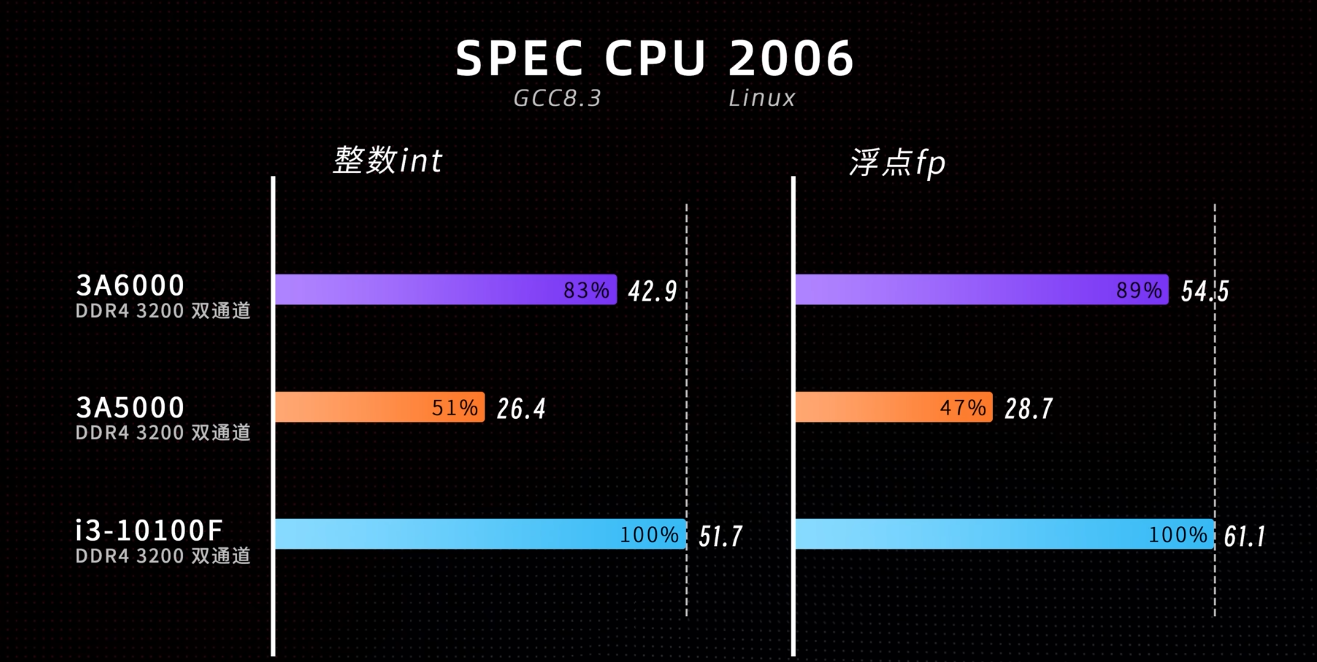
这个跑分是来自于视频,这些跑分是跑在旧世界,而不是新世界。之所以我不跑 SPEC 是因为想换一个赛道,每个自媒体或者博主都喜欢跑 SPEC 和苹果娱乐大师 Geekbench ,目前这些跑分首先我们不知道后面代码是否对某些平台有优化,另外作为新世界的 LoongArch 系统,应该给用户一个更加准确的信息。
跑分结果:
测试跑分成绩大家可以访问这个连接。
CloverLeaf 是一个 Lagrangian-Eulerian 流体动力学基准测试,广泛用于评估处理器的性能。它是 Phoronix Test Suite 中的一个测试项目,主要目的是通过模拟流体动力学问题来测试处理器在高性能计算(HPC)环境中的表现。
CloverLeaf 的主要目的是评估处理器在处理复杂计算任务时的性能,特别是那些涉及大量数据处理和计算的任务。它通过模拟流体动力学问题,测试处理器在以下几个方面的表现:
- 计算能力:评估处理器在执行复杂数学计算时的效率。
- 并行处理能力:测试处理器在多线程环境下的性能,特别是使用 OpenMP 进行并行计算时的表现。
- 内存带宽和延迟:评估处理器在处理大量数据时的内存访问效率。
- 浮点运算性能:测试处理器在执行浮点运算时的速度和效率。
CloverLeaf 可以反映处理器的以下性能特征:
- 多核性能:通过并行计算测试处理器的多核性能,评估其在多线程环境下的表现。
- 内存子系统性能:测试处理器在高带宽和低延迟内存访问方面的能力。
- 计算密集型任务处理能力:评估处理器在处理计算密集型任务时的效率,特别是涉及大量浮点运算的任务。
- 扩展性:测试处理器在增加计算负载时的扩展能力,评估其在高性能计算环境中的适应性。
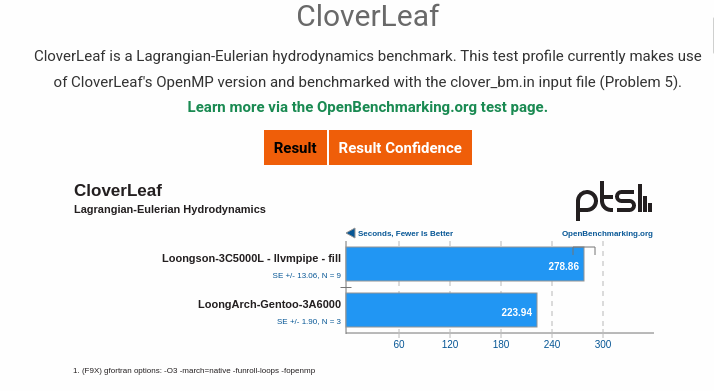
通过 CloverLeaf 能够提供一个全面的处理器性能评估,帮助用户了解处理器在高性能计算任务中的表现。这对于选择和优化处理器在科学计算、工程模拟等领域的应用具有重要参考价值。
那么 LoongArch 目前得分 223 分,大概排在以下这个位置:

CLOMP (C Livermore OpenMP)是一个用于评估OpenMP并行编程模型性能的基准测试套件。它的主要目的是:
- 测量OpenMP实现的开销,包括线程创建、同步和调度等方面的开销。
- 评估不同同步原语的性能影响,如barrier、critical section等。
- 研究不同线程调度策略的影响,如静态(static)、动态(dynamic)、guided等调度方式对性能的影响。
- 评估处理器在并行计算时的性能表现,包括可扩展性、内存访问模式等。
通过测试不同的工作负载和配置,CLOMP可以为OpenMP实现、编译器优化以及处理器设计提供宝贵的性能数据和见解。
CLOMP基准测试能够反映出处理器在以下几个方面的性能特征:
- 多线程并行处理能力: 通过测试不同线程数量的性能,可以评估处理器的多线程并行处理能力和可扩展性。
- 内存子系统性能: 由于CLOMP涉及大量数据访问,因此能够反映出处理器的内存带宽和延迟等内存子系统性能。
- 线程调度和同步开销: 不同的线程调度策略和同步原语会对性能产生影响,CLOMP可以量化这些开销。
- 浮点计算能力: 部分CLOMP测试用例包含大量浮点计算,能够评估处理器的浮点计算能力。
- 指令级并行度(ILP): CLOMP的部分测试用例对ILP有一定要求,可以反映出处理器的ILP能力。
CLOMP是一个全面的 OpenMP 基准测试套件,能够从多个角度评估处理器在并行计算环境下的性能表现,为系统设计和优化提供参考。
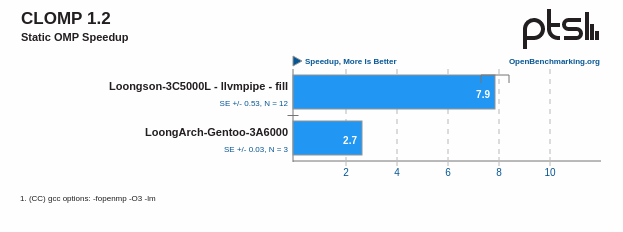
那么 LoongArch 目前得分 2.7 分,大概排在以下这个位置:

FFTE是一个用于计算一维、二维和三维序列的离散傅里叶变换(DFT)的软件包,其中序列的长度为 (2^p)(3^q)(5^r) 。测试目的包括:
- 评估处理器的计算能力:通过执行复杂的数学运算,FFTE可以测试处理器在执行高密度计算任务时的性能。
- 测量并行处理能力:如果FFTE利用了多线程或多核心,它可以用来评估处理器的并行处理能力。
- 测试内存带宽和延迟:由于FFTE在计算过程中可能需要频繁访问内存,它可以用来评估处理器的内存子系统性能。
基于FFTE的特性,它能反映处理器的以下性能特征:
- 浮点运算性能:FFTE执行大量的浮点运算,因此可以测试处理器在浮点计算方面的性能。
- 多核和多线程性能:如果FFTE采用了并行计算技术,它可以评估处理器在多核和多线程环境下的性能。
- 内存性能:FFTE的计算可能涉及大量的内存访问,因此可以用来评估处理器的内存带宽和延迟。
- 指令级并行(ILP)和数据级并行(DLP)能力:FFTE的计算可能需要处理器同时执行多个操作,从而测试处理器的ILP和DLP能力。
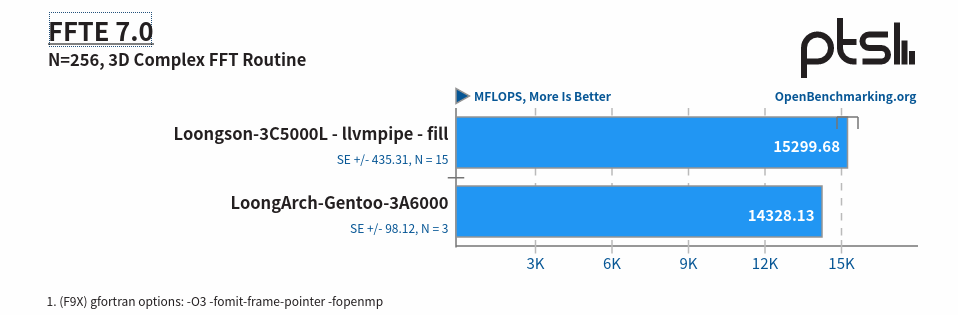
这里大家可以看到,大概 LoongArch 有 14328 分,如果和 x86 对比差不多在这个位置:
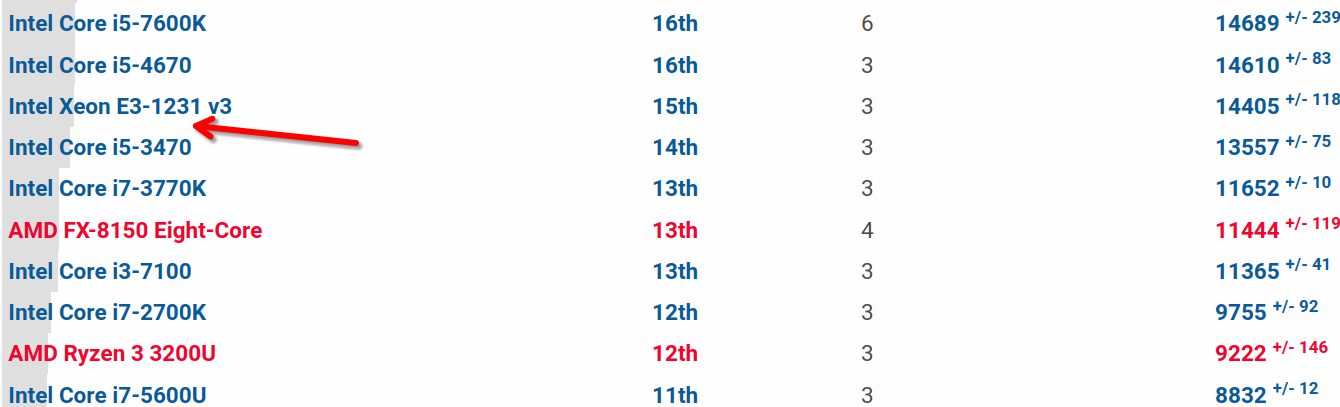
Fhourstones 基准测试,解决了 Connect-4 游戏中的位置问题,游戏在一个垂直的 7×6 棋盘上进行。这个测试使用了 64MB 的转置表(transposition table)和 twobig 替换策略。位置表示为 64 位的位板(bitboards),哈希函数通过单个 64 位模运算计算,这使得 64 位机器在性能上有一定优势。Alpha-beta 搜索器基于历史启发式动态排序移动。
它的主要目的是评估处理器在处理复杂计算任务时的性能,特别是涉及大量数据操作和搜索算法的任务。通过解决 Connect-4 游戏中的位置问题,测试可以模拟处理器在执行类似任务时的表现。并能反应处理器如下特性:
- 整数运算性能:由于位置表示为 64 位的位板,并且哈希函数使用 64 位模运算,这个测试可以很好地反映处理器在执行整数运算时的性能。
- 内存访问效率:使用 64MB 的转置表来存储和检索游戏位置,这可以测试处理器的内存访问速度和缓存效率。
- 搜索算法效率:Alpha-beta 搜索算法需要大量的计算和数据操作,这可以测试处理器在执行复杂算法时的效率。
- 多线程性能:如果测试在多核处理器上运行,可以评估处理器在并行计算任务中的表现。
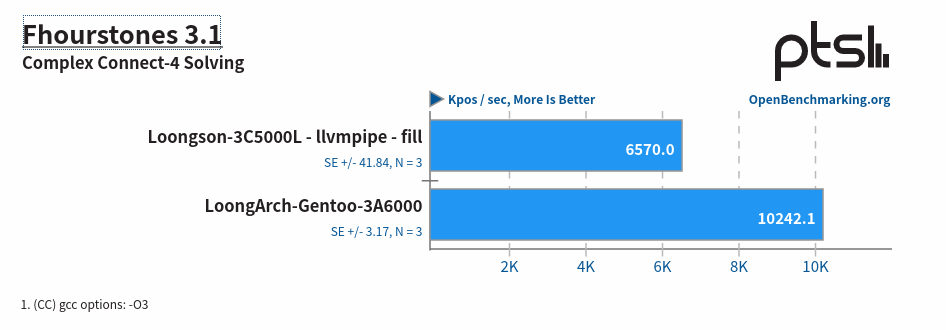
和 x86 对比的情况如下图所示:
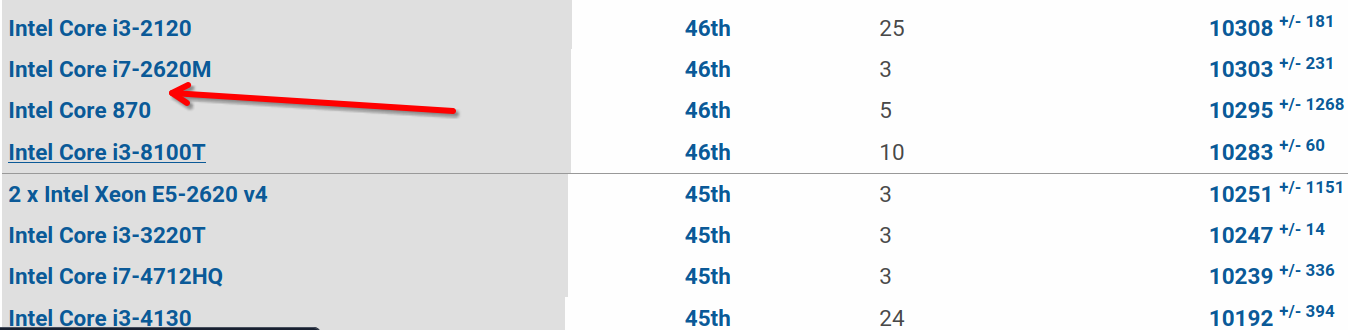
x265 编码测试是一个简单的测试,旨在评估处理器在进行 H.265 视频编码时的性能。该测试在 CPU 上运行 x265 编码器,提供 1080p 和 4K 两种选项,用于 H.265 视频编码性能的评估。
目的是评估处理器在处理视频编码任务时的性能。通过对 1080p 和 4K 视频进行 H.265 编码,可以模拟处理器在执行高负载、多线程计算任务时的表现,并能反应处理器如下的特性:
- 整数运算性能:由于视频编码涉及大量的整数运算,特别是位操作和模运算,这个测试可以很好地反映处理器在执行整数运算时的性能。
- 多线程性能:x265 编码器能够利用多核处理器的优势,因此这个测试可以评估处理器在多线程环境下的表现。处理器的核心数量和线程管理能力在这里尤为重要。
- 内存访问效率:视频编码过程中需要频繁访问内存,测试可以反映处理器的内存带宽和缓存效率。
- 指令集优化:一些处理器支持高级指令集(如 AVX-512),这些指令集可以显著提高视频编码的效率。测试可以评估处理器在使用这些指令集时的性能提升
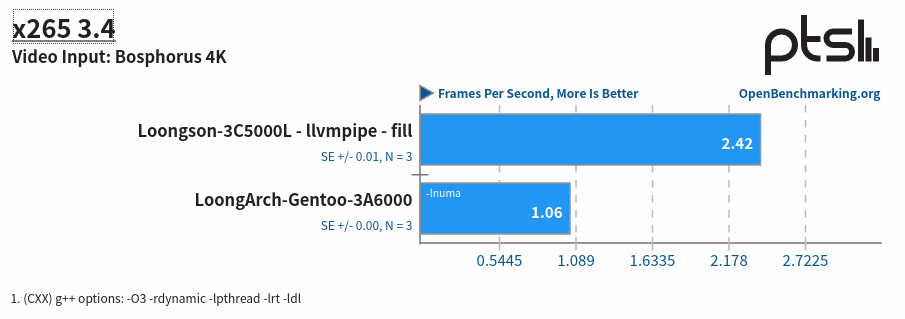
如果和 x86 相比,目前处于如下这个位置:
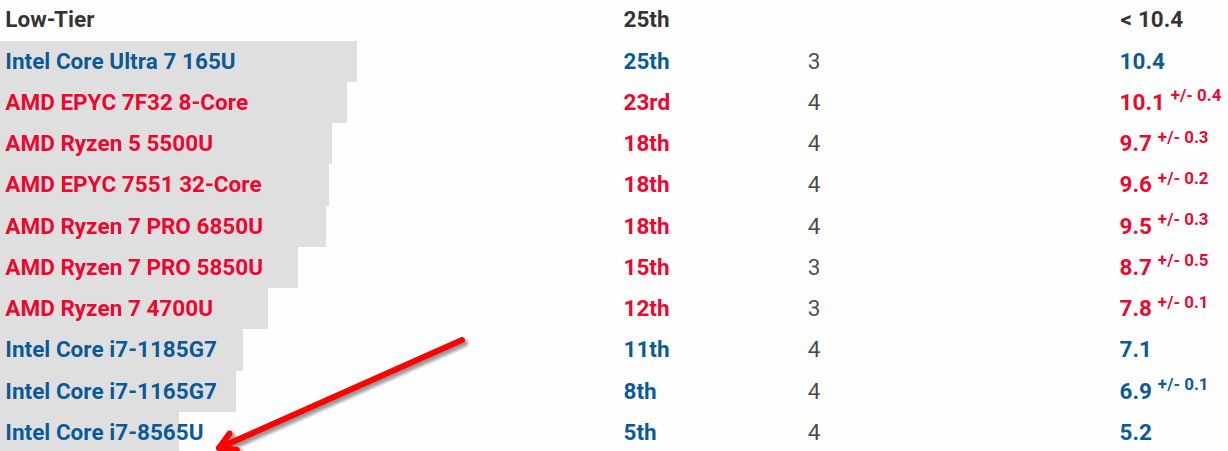
EEMBC CoreMark 基准测试是一个专门用于评估处理器核心性能的测试。CoreMark 由嵌入式微处理器基准测试联盟(EEMBC)开发,旨在成为行业标准,替代传统的 Dhrystone 基准测试。
CoreMark 测试的主要目的是评估处理器核心的基本功能和性能。它通过执行一系列常见的算法和数据结构操作来衡量处理器的性能。这些操作包括列表处理(查找和排序)、矩阵操作(常见的矩阵运算)、有限状态机(确定输入流是否包含有效数字)和循环冗余校验(CRC),并能够反应处理器如下特性:
- 整数运算性能:CoreMark 包含多种整数运算任务,如列表处理和矩阵操作,这些任务可以反映处理器在执行整数运算时的效率[2][5][15]。
- 流水线操作:测试处理器的基本流水线结构,评估其在处理基本指令和操作时的效率。
- 内存访问效率:虽然 CoreMark 主要关注处理器核心,但它也涉及基本的内存访问操作,测试处理器在处理内存读写时的性能。
- 控制操作:CoreMark 还测试处理器的控制操作能力,如状态机操作,这对于评估处理器在处理复杂控制逻辑时的性能非常重要。
- 多线程性能:CoreMark 支持多线程执行,可以评估处理器在多线程环境下的扩展性和性能。
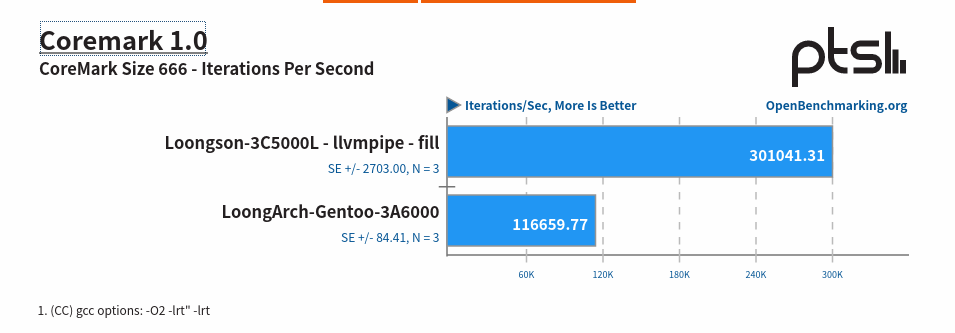
和 x86 相比的情况如下:
C-Ray 是一个简单的多线程光线追踪器,旨在测试处理器的浮点运算性能。该测试通过生成 1600 x 1200 的图像,并为每个像素发射 8 条光线进行抗锯齿处理,来评估处理器的性能。
主要目的是评估处理器在执行浮点运算时的性能。光线追踪是一种计算密集型任务,涉及大量的浮点运算,因此这个测试可以很好地反映处理器在处理复杂计算任务时的表现。并反映处理器如下特性:
- 浮点运算性能:C-Ray 测试主要关注处理器的浮点运算能力。光线追踪算法需要大量的浮点乘法和加法操作,这些操作可以测试处理器的浮点单元(FPU)的效率。
- 多线程性能:C-Ray 测试是多线程的,每个核心支持 16 个线程。这可以评估处理器在多线程环境下的扩展性和性能,特别是处理器在并行计算任务中的表现。
- 缓存和内存访问效率:虽然 C-Ray 测试主要在 L1 缓存中运行,但它仍然可以反映处理器的缓存和内存访问效率。高效的缓存和内存管理对于提高浮点运算性能至关重要。
- 指令集优化:C-Ray 测试可以利用处理器的高级指令集(如 AVX),这些指令集可以显著提高浮点运算的效率。测试可以评估处理器在使用这些指令集时的性能提升。
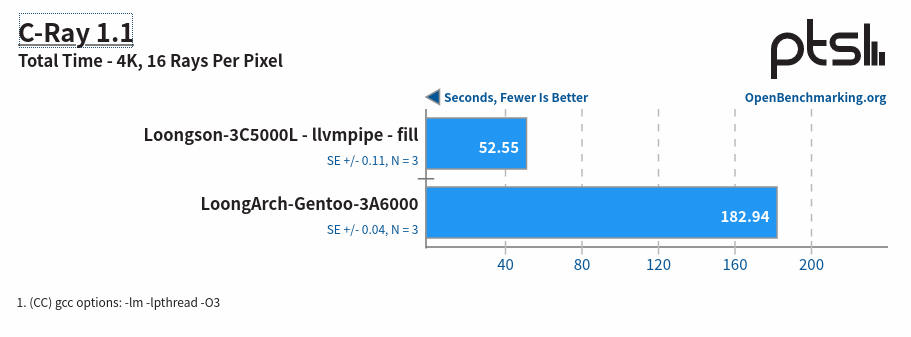
如果和 x86 相比,情况如下:

POV-Ray 测试是一个用于评估处理器性能的基准测试,特别是针对 3D 图形渲染任务。POV-Ray(Persistence of Vision Raytracer)是一款使用光线追踪技术创建 3D 图形的程序。
POV-Ray 测试的主要目的是评估处理器在执行复杂 3D 渲染任务时的性能。光线追踪是一种计算密集型任务,涉及大量的浮点运算和内存访问,因此这个测试可以很好地反映处理器在处理高负载计算任务时的表现。
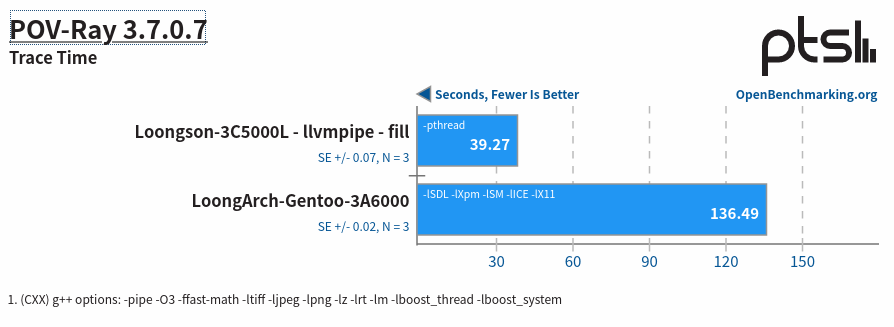
对应 x86 ,我的龙芯情况如下:

结语
以上内容只是其中一些典型的测试结果,不过从中我们不难发现,龙芯 3A6000 的性能比大部分认为的接近 10 代 i3,还是太乐观了。大家可以访问这个测试的完整连接。详细理解。


这里每个测试都在强调多线程性能,我觉得非常正确。将来的计算普遍都会是大量并行,多线程并发,同步开销,原子操作时延等指标比单核性能要重要得多。
是的,多线程并行和存算一体将是真正未来需要的